
增删改查操作
一、CRUD简介
CURD是对数据库中的记录进行基本的增删改查操作:
C -> create 创建
R -> retrieve 读取
U -> update 更新
D -> delete 删除
二、create 新增
CURD是对数据库中的记录进行基本的增删改查操作
insert
insert into 表名 values(值,值)
2.1 指定列插入
2.1.1 单行数据全列插入
create table student(id bigint ,name varchar(50),gender varchar(20);
insert into student values (1,'秃然醒悟');
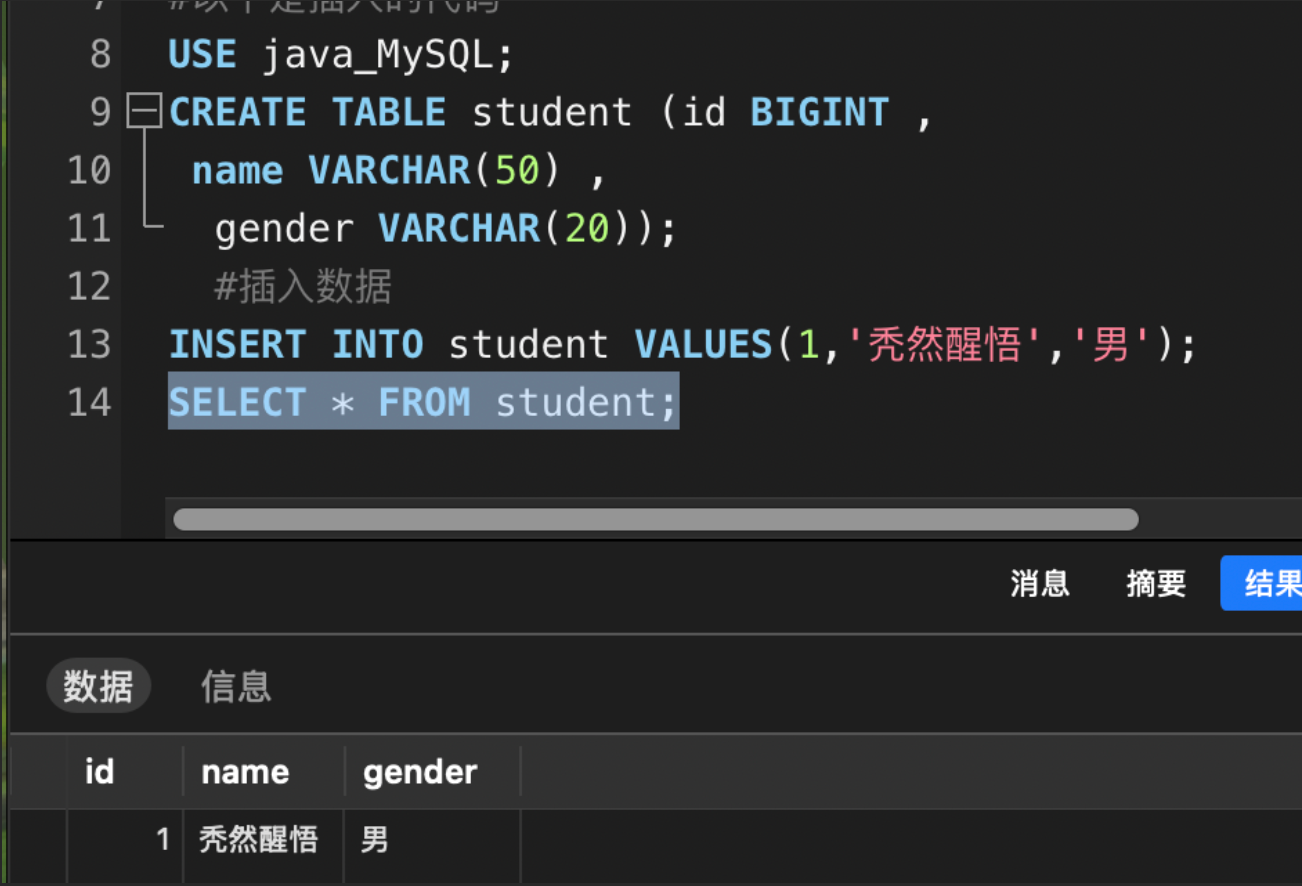
这个时候我们来查询一下是否插入成功:
SELECT * FROM student;

2.1.2 单行数据指定列插入
//只插入姓名和性别
insert into student (name,gender) values ('张三','男');
//只插入性别和id
insert into student (gender,id) values ('女',123123);
//查询一些表内
select * from student;
2.1.3 一次insert插入多个记录
insert into student values (3 ,'赵六' , '女')
, (4 , '田七' , '男')
,(5 , '王五' , '女');
我们编译的时候,会提示我们当前操作影响到几行。就像我们现在插入三行那就是影响了三行。
通过这样的插入,只是客户端和服务器之间**只进行了一次网络通信**,如果我们分成三个insert来插入那我们就会有三次网络通信。
网络通信是有一定的开销的,所以我们的网络通好点会更好。
当然也可以针对某一列来插入多个记录:
insert into student (id) values (1),(2),(3);
三、查询
3.1 全列查询
把一个表的所有列和所有行全部查询
select * from 表名;
//例如
select * from student;
此处select的* 的 *代表的是所有的列。
全列查询是一个非常危险的操作!!!,全列查询会把表中的所有数据都查询出来,会涉及到大量的硬盘访问和网络访问。
如果数据很大进行select * 的话,数据库服务器所在的极其的硬盘和网络瞬间会吃满,这样的话用户这边就会看到程序不能正常工作了。
3.2 指定列查询
比如一个几十个列,我们只需3个列就行。
select 列名,列名.... from 表名;
//例如
select id from student;
select id,name from student;
3.3 查询时带有表达式
一边查一边进行计算,进行简单的统计
create table exam(id bigint ,
name varchar(20),
chinese float comment '语文成绩',
math float COMMENT '数学成绩',
english float COMMENT '英语成绩');
--插入数据
insert into exam (name,chinese,math,english) values(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87, 78, 77),
(3, '猪悟能',88,98,90),
(4, '曹孟德',82,84,67),
(5, '刘玄德',55,85,45),
(6, '孙权',70,73,78),
(7, '宋公明',75,65,30);
3.4 查询带有别名
select 表达式 as 别名 from 表名;
//例如
select Chinese + math + english as total from exam;
select name as '姓名' , Chinese + math + english as '总成绩' from exam;
3.5 针对查询结果去重
select distinct 列名 from 表名;
--例如我们来查询数学这一列有没有一样的
select distinct math from exma;
--注意,当指定多个列去重的时候要求多个列都是共同的值
当我们查询到有相同的值就会合并在一起。
3.6 条件查询
根据查询条件,对于查询的行进行筛选。条件处理,这一行作为查询结果;不成立则跳过。
3.6.1 比较运算符
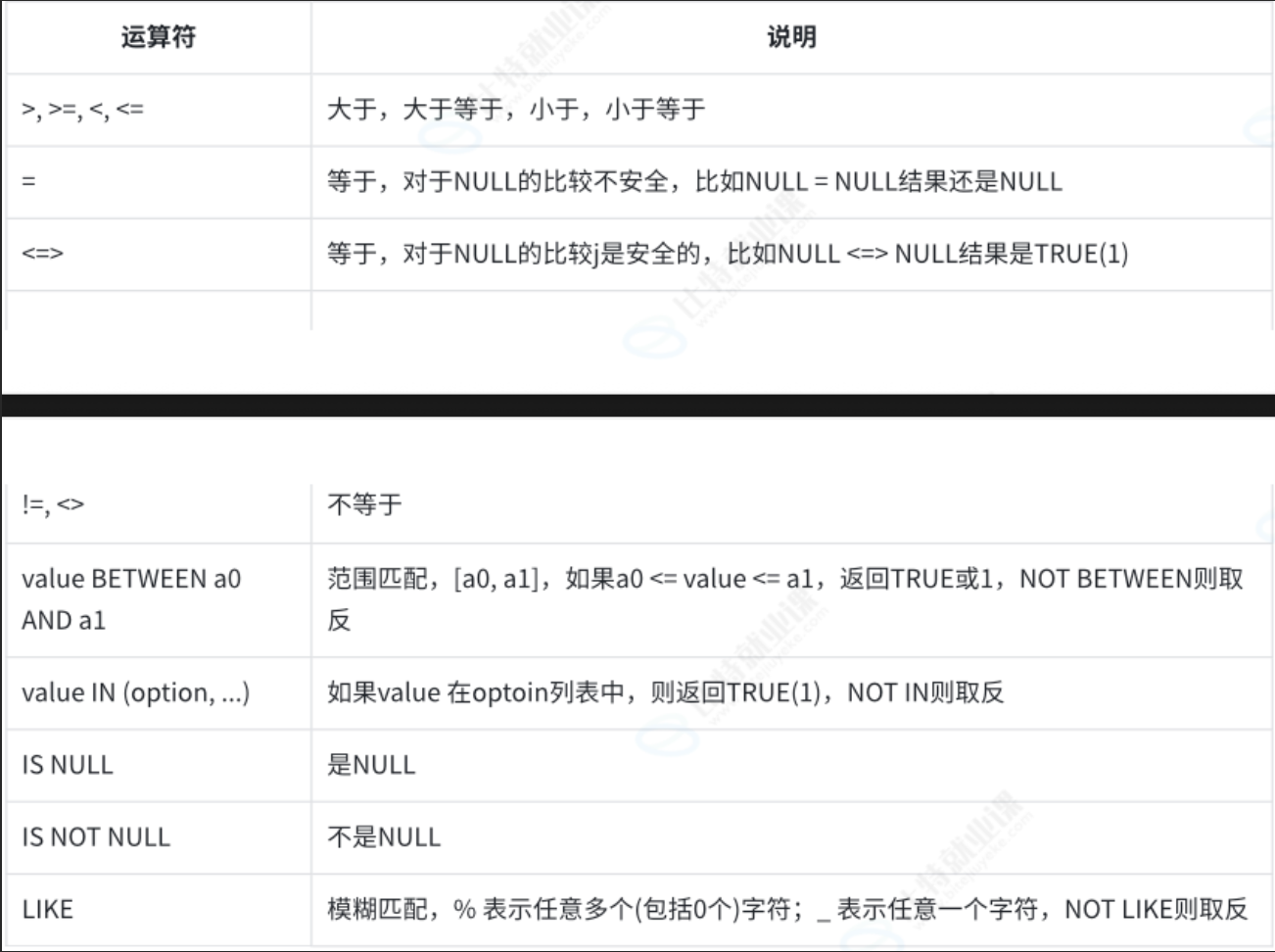

value BETWEEN a0 AND a1:看value的值是否在[a0,a1]闭区间中
value IN :判断value是否在集合中
IS NULL / IS NOT NULL:列名<=>NUll 或 列名 is NULL
LIKE : 模糊匹配
3.6.2 逻辑运算符


3.6.3 示例
3.6.3.1 基本查询
查询英语不及格的同学及英语成绩 (< 60)
--选择exam表里的name和English两列,判断是否小于60.
select name,english from exam where english < 60;
--也可以不用name,english
select name from exam where english < 60;--这样只会显示小于60的名字
本质上就是拿着表里的数据遍历,在遍历的同时就像条件判断。
3.6.3.2 查询语文成绩高于英语成绩的同学
//直显示语文分数高于英语分数的人的名字
select name from exam where chinese > english;
3.6.3.3 总分在 200 分以下的同学
select name,chinese,math,english from exam where chinese + math + english < 200;
但是注意下面这个写法
--这是错误的写法
select name,chinese+math+english as total from exam where total < 200;
原因如下(主要是条件判断的原理所决定的):
先遍历表格
取出表的每一行,带入条件 (这一块使用的别名)
把符合条件的行筛选出来
根据select后面指定的表达式进行计算 (这一块定义的别名)
3.6.3.4 AND和OR
查询语文成绩大于80分且英语成绩大于80分的同学
3.6.3.x 模糊查询
like搭配通配符 -> %和__。
%代表任意个任意字符;__代表一个任意字符。
查询所有姓孙的同学
select * from exam where name like '孙%';
--查找一个以孙结尾的同学
select * from exam where name like '%孙';
正则表达式:字符串匹配更广泛使用的方案(SQL不适用)。
通过特殊符号,定义了字符串的“筛选规则”。通过特殊字符定义筛选规则。
3.7 排序查询:
select 列名 from 表名 order by 列名
--默认为升序排序
--例如:在exam表里以Chinese为目标按照降序来排序
select * from exam order by chinese desc;
--先按照数学成绩从小到大排序,再按照英语
select * from exam order by math,english;
排序查询也是针对“临时表”操作的,不影响数据库服务器硬盘上存储的原始数据
默认是升序排序,也可以写asc来表示升序排序。降序排序是desc。
3.7.1 查询同学的总分,由高到低排序
select name,chinese + math + english from exam order by chinese + math + english desc;
在order by中是可以使用别名作为排序规则的
select name,chinese + math + english as total from exam order by total desc;
区别于前面。order by执行顺序实在表达式计算之后的,别名先定义出来了再执行order by。
3.7.2 加入条件
先进行筛选再排序
--先筛选空再对语文排序
select name,chinese from exam where chinese is not NULL order by chinese;
3.8 分页查询
把所有数据存放在一页里展现出来:用户看不完,程序运行成本高。
这样我们就可以使用分页的效果来解决
select 列名 from 表名 where 条件 order by 列名 limit N;
--limit N; N是数字,约定这一页最多返回多少条记录
--limit子句来实现分页查询
--获取到前N条数据
--描述了从第M条记录开始(从0开始),往后获取N条记录
limit N offset M;--offset为“偏移量”,相当于“数组下标”
一页有三条数据:
select * from exam limit 3 offset 9;
--也可以这么写(不推荐)
select * from exam limit 9,3;
不会存在“下标越界”的情况,最多得到一个空
3.8.1 总成绩前三的同学
select name,chinese + math + english as total
from exam
where chinese is not NULL and math is not NULL and english is not NULL
order by total desc
limit 3;
四、update修改
4.1 语法
update 表名 set 列名 = 值 where条件/order by列名/limit N;
4.2示例
4.2.1 修改值
将孙悟空同学的数学成绩改成80
update exam set math = 80 where name = '孙悟空';
-- 这里的=相当于赋值了
update是修改的原始数据不是“临时表”!!
同时修改多个值:
4.2.2 多条件修改
把曹孟德的数学成绩改成60,语文成绩改成70
select exam set math = 60,chinese = 70
where name = '曹孟德';
把总成绩倒数前三的三个同学的数学成绩加上30分
--我们先查询一下倒数前三的三个同学
select * from exam
where chinese is not NULL and math is not NULL and english is not NULL
order by chinese + english + math asc limit 3;
--加上30分
update exam set math = math + 30;
where chinese is not NULL and math is not NULL and english is not NULL
order by chinese + english + math asc limit 3;
4.2.3 修改所有
给所有语文成绩翻倍
如果不指定任何条件就会针对所有的数据进行 修改
update exam set chinese = chinese * 2;
五、delete 删除
5.1 语法
delete from 表名 where条件/order by列名/limit N;
通过这些条件等子句限定要删除哪些内容,如果不写条件就会删除所有数据
5.2 示例
5.2.1 删除数据
delete from exam where name = '孙悟空';
delete from exam where math is null and chinese is null and english is null;
--删除表
delete from exam;
六、插入查询结果
把查询的结果插入到另一个表里
insert into 表名 select 列名 from 表名 ......;
6.1 示例
create table student (id int ,name varchar (20));
create table student2 (id int ,name varchar (20));
insert into student values (1,'张三'),(2,'李四'),(3,'王五');
--插入三行并且查询
insert into student2 select * from student;
--只插入name这一列并且只查询name
insert into student2 (name) select name from student;
七、聚合函数
聚合函数是为了进行聚合查询的。聚合函数可以理解为SQL的库函数。
聚合查询就是再进行“行和列之间进行运算”。
count ->查询到的数据的数量
sum -> 必须是数字,求和
avg -> 必须是数字,平均值
max -> 必须是数字,最大值
min -> 必须是数字,最小值
7.1 统计exam表记录
实际开发中,SQL一般会把建表和建库的操作写到以一个单独的文件中1,后续重新建表,直接把建表语句批量执行。
使用IDEA创建一个xxx.sql的文件,后续说。
7.2 COUNT
select count(*) from exam;
--这里面不要乱加空格
select count (*) from exam;
--这样SQL可能会以为count是个列名 (*)是别名
count只支持一个参数
--查询chinese这一列有行
select count(chinese) from exam;
--下面这个是错误的
select count(chinese,math) from exam;
注意:count(*)是可以把NULL也包含进去,但是count(列)就不能包含。
7.3 SUM
统计所有学生的数学总分
select sum(math) from exam;
--非数字的列只会得到NULL
select sum(name) from exam;
sum()里也可以是表达式:求所有学生总成绩的总成绩
select sum(chinese + math + english) from exam;
7.4 AVG
统计学生英语平均分:
select avg(english) from exam;
7.5 MAX和MIN
找出数学的最大值和英语的最小值
select max(math)
八、Group by 分组查询
把表的若干行进行分组,需要指定“分组依据”,指定某个列,这个列值相同的行就会分到一个组里。会根据分组后的结果进行聚合查询
8.1 语法
select 表达式 from 表名 group by 列名;
8.2 示例
先创一个新表


统计每个角色的人数
--先用name进行分组,再针对role这一列进行分组
select role , count(name) from emp group by role;
结果为3、2、1
统计每个角色的平均工资、最高工资、最低工资
select role , avg(salary),max(salary),min(salary)
from emp
grout by role;
8.3 having子句
分组之前指定条件:where
分组之后指定条件:having
--分组之后
--再group by的前面
--先针对原有的表进行筛选,把张三去掉。然后再执行下面的操作
select role,avr(salary) from emp where name != '张三' group by role;
统计每个岗位的平均薪资,保留平均薪资小于15000的人
--分组之前
--再group by的后面
--先聚合,把小于15000的人筛选出来后再操作
--也就是分组之后指定条件
slelct role,avg(salary) from emp group by role having avg(salary) < 15000;
分组前的条件和之后的条件可以同时包含:统计每个岗位的平均薪资,先去掉张三,再保留平均薪资小于15000的人
select role,avg(salary) from emp where name != '张三'
group by role having avg(salary) < 15000;
九、内置函数

9.1 日期函数
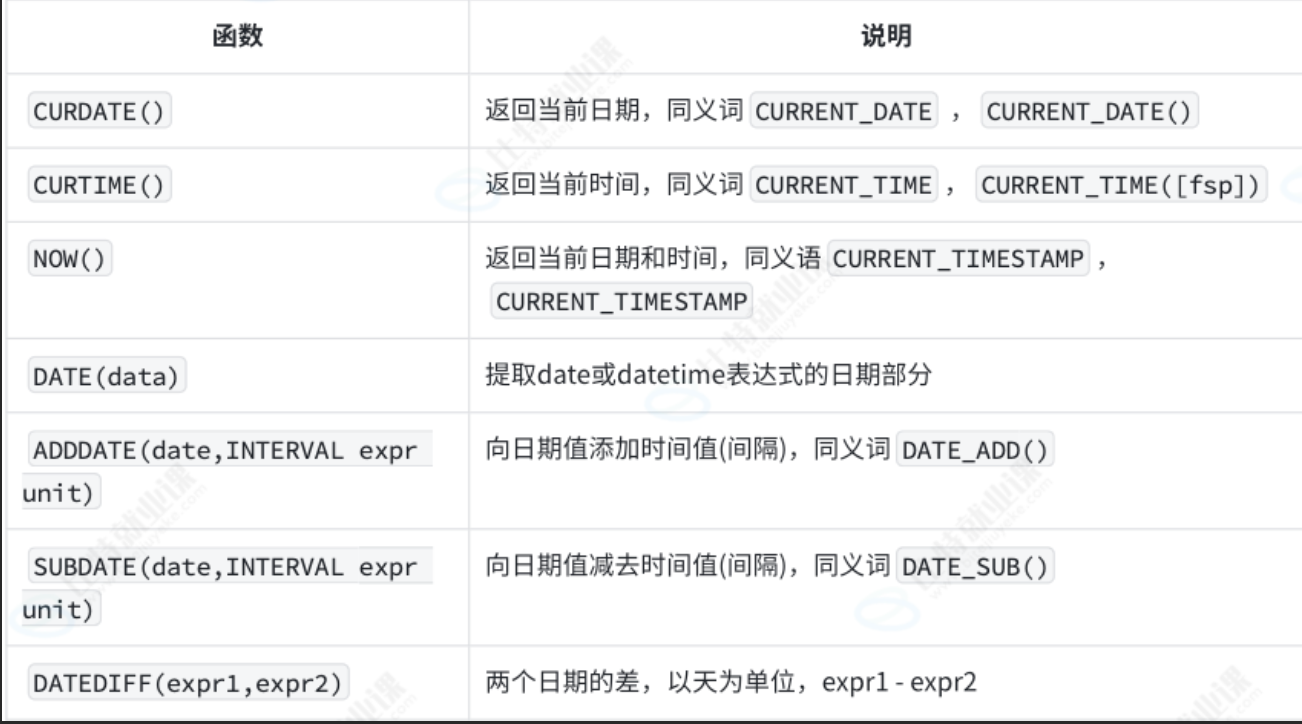
SQL中的函数调用一般都是通过select语句进行的,把函数放到select这里的列。查询结果就是函数调用返回的结果。
select curdate();--调用curdate函数,只包含年月日
--写列from表名之后就是再遍历表的每一行
select * from emp;
select curtime();--只显示时分秒
--显示年月日时分秒
select now();
--针对已有的时间日期进行提取操作
--先创建一个新的表
create table student(id int,name varchar(20),last_login_time datetime);
--插入数据
insert into student values(1,'张三','2026-01-28 15:56:00');
insert into student values(1,'张三',now());
--now()获取到的时间是系统时间
--展示一下
show student;
select name,date(last_login_time) from student;
select adddate('2025-09-29',interval 3 day);
select adddate('2025-09-29',interval 3 month);
select adddate('2025-09-29',interval 3 year);
select adddate('2025-09-29',interval 3 week);
--计算日期差值
select datediff('2025-01-19','2026-01-28')
9.2 字符串函数
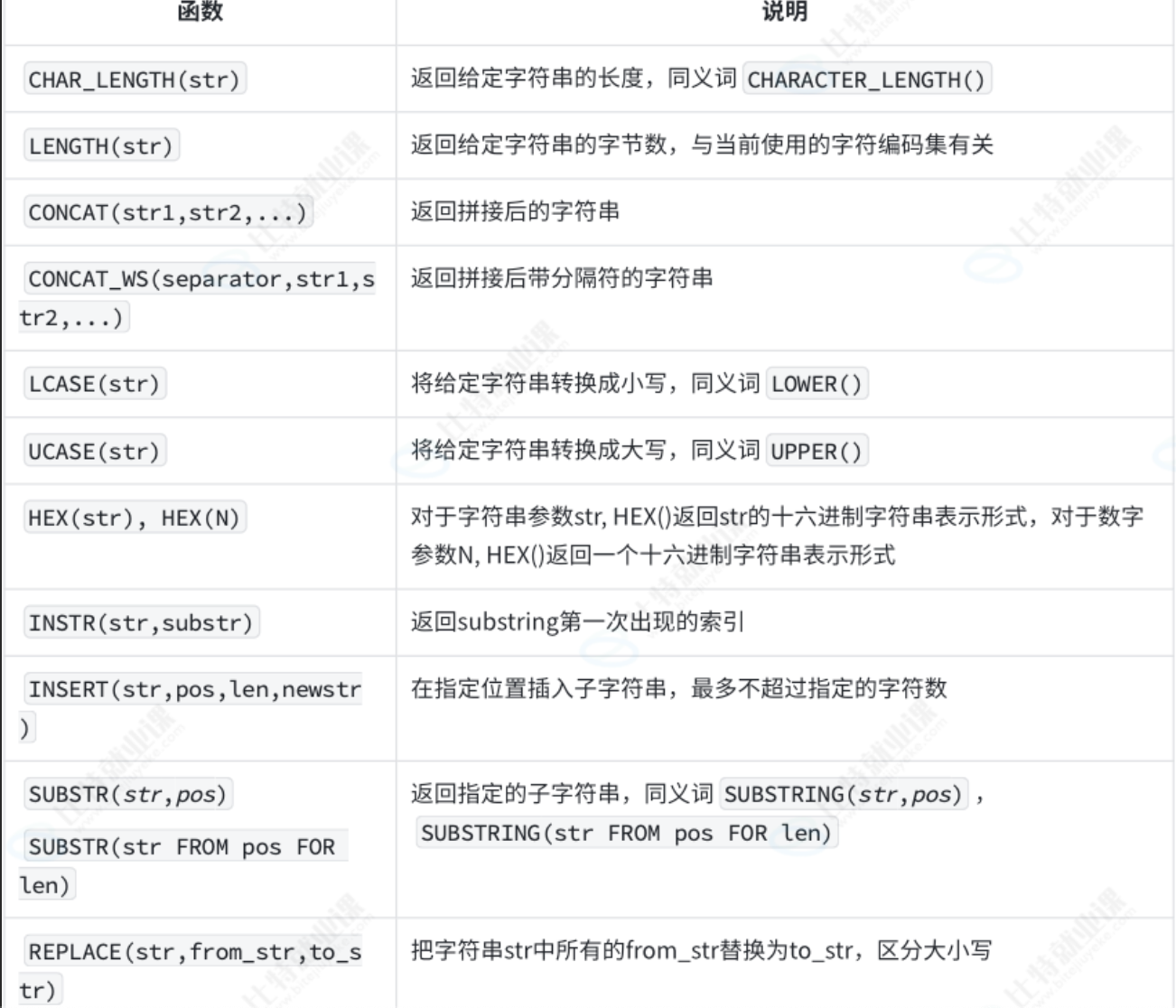
char_length和lenght:
--length(name):字数 char_lenght(name):字节数
select name,length(name),char_lenght(name) from student;
concat:
select concat(name,'同学') from student;
--多个
select concat(name,'同学','上次登录时间'+ last_login_time) from student;
concat_ws:
--带有分隔符的拼接
select concat_ws('|','a','b','c');
9.3 数学函数
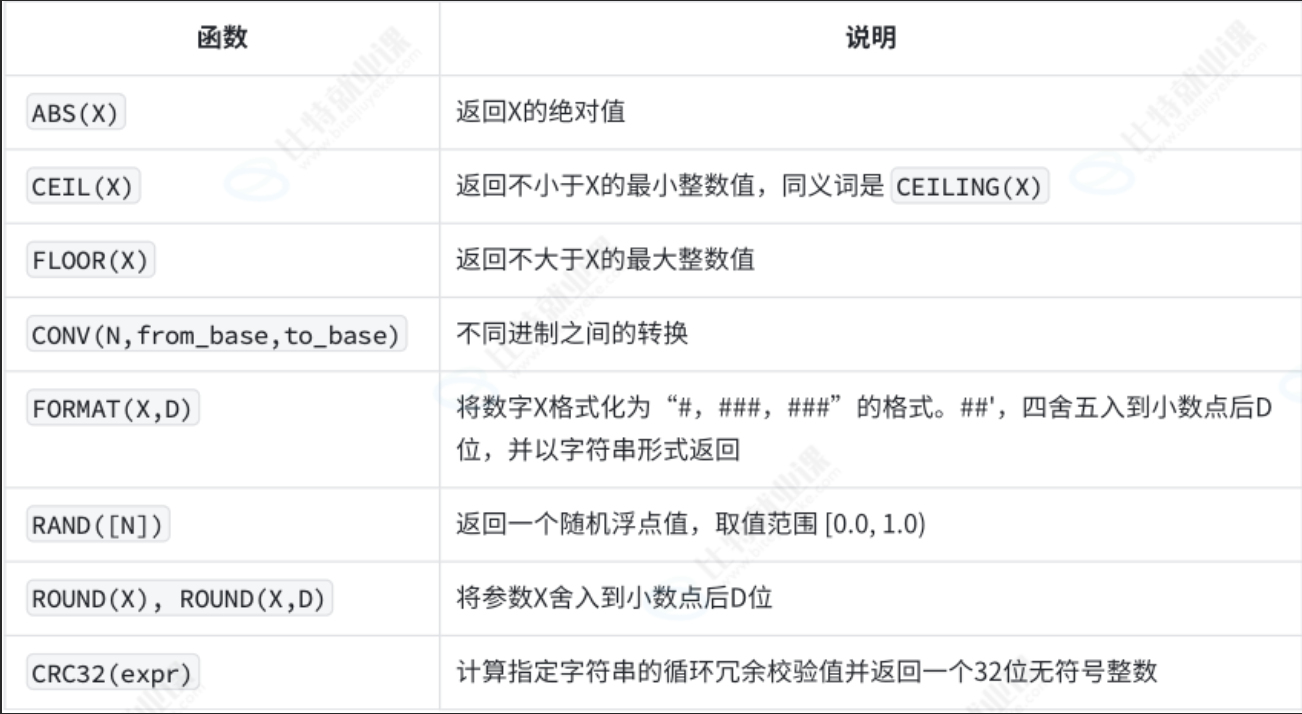
9.4 其他函数


- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝







